您现在的位置是:主页 > news > 乐基儿做黎明网站的女郎/百度直播平台
乐基儿做黎明网站的女郎/百度直播平台
![]() admin2025/4/29 1:34:47【news】
admin2025/4/29 1:34:47【news】
简介乐基儿做黎明网站的女郎,百度直播平台,西安草坪网站建设,网站挂标 怎么做基于Darknet框架利用YOLOV3/V4跑通自己数据 一、Darknet框架安装 YOLOV3:https://github.com/pjreddie/darknet YOLOV4:https://github.com/AlexeyAB/darknet 注:由于V3和V4内部有一些区别,具体的不同可看我之前写的一篇blogYOLOV4与YOLOV3的区别&…
基于Darknet框架利用YOLOV3/V4跑通自己数据
一、Darknet框架安装
YOLOV3:https://github.com/pjreddie/darknet
YOLOV4:https://github.com/AlexeyAB/darknet
注:由于V3和V4内部有一些区别,具体的不同可看我之前写的一篇blogYOLOV4与YOLOV3的区别,所以要根据你的需求下载不同版本的框架源码(我用v4为例子)。

其中,打开Makefile文件:
GPU=0 #是否打开GPU,1-打开,0-关闭
CUDNN=0 #同时打开gpu和cudnn才能进行gpu加速
CUDNN_HALF=0 #对于TITAN v100等显卡,打开这个选项,速度还能提升3倍多
OPENCV=0 #是否打开opencv,其实在darknet中,你是否编译opencv都无关紧要,区别在于后续可视化方面
AVX=0 #如果想要进行cpu加速的话,打开这个选项,但是如果报错,就恢复成0
OPENMP=0 #同上AVX
LIBSO=0
ZED_CAMERA=0
ZED_CAMERA_v2_8=0
ARCH= -gencode arch=compute_35,code=sm_35 \-gencode arch=compute_50,code=[sm_50,compute_50] \-gencode arch=compute_52,code=[sm_52,compute_52] \-gencode arch=compute_61,code=[sm_61,compute_61]
上述是要根据你自己的显卡算力进行设置的,作者已经把常见的显卡设置的算力注释起来了,可以根据自己需要设置:
# GeForce RTX 3070, 3080, 3090
# ARCH= -gencode arch=compute_86,code=[sm_86,compute_86]# Kepler GeForce GTX 770, GTX 760, GT 740
# ARCH= -gencode arch=compute_30,code=sm_30# Tesla A100 (GA100), DGX-A100, RTX 3080
# ARCH= -gencode arch=compute_80,code=[sm_80,compute_80]# Tesla V100
# ARCH= -gencode arch=compute_70,code=[sm_70,compute_70]# GeForce RTX 2080 Ti, RTX 2080, RTX 2070, Quadro RTX 8000, Quadro RTX 6000, Quadro RTX 5000, Tesla T4, XNOR Tensor Cores
# ARCH= -gencode arch=compute_75,code=[sm_75,compute_75]# Jetson XAVIER
# ARCH= -gencode arch=compute_72,code=[sm_72,compute_72]# GTX 1080, GTX 1070, GTX 1060, GTX 1050, GTX 1030, Titan Xp, Tesla P40, Tesla P4
# ARCH= -gencode arch=compute_61,code=sm_61 -gencode arch=compute_61,code=compute_61# GP100/Tesla P100 - DGX-1
# ARCH= -gencode arch=compute_60,code=sm_60# For Jetson TX1, Tegra X1, DRIVE CX, DRIVE PX - uncomment:
# ARCH= -gencode arch=compute_53,code=[sm_53,compute_53]# For Jetson Tx2 or Drive-PX2 uncomment:
# ARCH= -gencode arch=compute_62,code=[sm_62,compute_62]# For Tesla GA10x cards, RTX 3090, RTX 3080, RTX 3070, RTX A6000, RTX A40 uncomment:
# ARCH= -gencode arch=compute_86,code=[sm_86,compute_86]
设置完Makefile:
cd darknet-master
make -j24
二、源码分析
- cfg/ : 目录下面有很多.cfg文件,类似caffe的prototxt文件,包含网络结构,学习参数等
- data/ : 存放训练数据和标注文件,.name文件存放类别名。labels/下有ASCII码32-127的8种尺寸的图片,显示标签用。
- examples/ : 例程代码
- include/ : darknet.h
- obj/ : 编译中间文件
- python/ : karknet.py , darknet.pyc , proverbot.py
- scipts/ : 有关训练集索引文件的脚本
- src/ : 源码
- backup/ : 目录下保存训练产生的权重文件,初始为空文件夹
三、训练
3.1数据集的准备
darknet的标准数据集是VOC,之前在这个blog上面已经说过了跑通caffe-ssd demo代码(训练、测试自己数据集)

Annotations:这个文件夹装的是已经进行人工标注之后的xml文件(但是在darknet框架中,不是直接用darknet,而是使用的是经过转化之后的txt文件)
Imagesets:存放一些txt文件,例如train.txt,test.txt
JPEGImages:存放原始训练照片数据的文件夹
3.2 xml转化为txt
# 此代码和data文件夹同目录
import glob
import xml.etree.ElementTree as ET# 类名
class_names = ['', ''] #该位置修改为你数据集的类别
path = '' #xml文件路径,train_images只需改为val_images就可以处理val_images的了# 转换一个xml文件为txt
def single_xml_to_txt(xml_file):tree = ET.parse(xml_file)root = tree.getroot()# 保存的txt文件路径txt_file = xml_file.split('.')[0]+'.txt'with open(txt_file, 'w') as txt_file:for member in root.findall('object'):# filename = root.find('filename').textpicture_width = int(root.find('size')[0].text)picture_height = int(root.find('size')[1].text)class_name = member[0].text# 类名对应的indexclass_num = class_names.index(class_name)box_x_min = int(member[4][0].text) # 左上角横坐标box_y_min = int(member[4][1].text) # 左上角纵坐标box_x_max = int(member[4][2].text) # 右下角横坐标box_y_max = int(member[4][3].text) # 右下角纵坐标# 转成相对位置和宽高x_center = (box_x_min + box_x_max) / (2 * picture_width)y_center = (box_y_min + box_y_max) / (2 * picture_height)width = (box_x_max - box_x_min) / picture_widthheight = (box_y_max - box_y_min) / picture_heightprint(class_num, x_center, y_center, width, height)txt_file.write(str(class_num) + ' ' + str(x_center) + ' ' + str(y_center) + ' ' + str(width) + ' ' + str(height) + '\n')# 转换文件夹下的所有xml文件为txt
def dir_xml_to_txt(path):for xml_file in glob.glob(path + '*.xml'):single_xml_to_txt(xml_file)dir_xml_to_txt(path)


上述就是转化的效果。(xml文件可以删除了)
3.3 生成train.txt 和 val.txt
先说明下,这两个txt文件是保存所有训练和测试图片名称的。
- train.txt文件包含train_images中所有图片的路径,每个图片一行
- val.txt文件包含val_images中所有图片的路径,每个图片一行
import glob
path = '' #存放图片的文件夹,即JPEGImagesdef generate_train_and_val(image_path, txt_file):with open(txt_file, 'w') as tf:for jpg_file in glob.glob(image_path + '*.jpg'):tf.write(jpg_file + '\n')generate_train_and_val(path + 'train_images/', path + 'train.txt')
generate_train_and_val(path + 'val_images/', path + 'val.txt')
3.4准备data文件和names文件
names文件:

这个文件是存放你训练数据的类别名称,每个类别占一行,我训练的数据就两类。
data文件:

3.5 准备预训练权重文件(这一步其实可以省略,但是为了训练效率,建议加上)
yolov3预训练权重
3.6 准备cfg文件
作者已经给我们提供了yolov3的cfg文件,在darknet-master/cfg下面,打开yolov3.cfg:
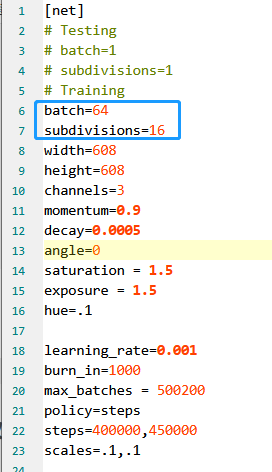
在darknet的配置文件有两个参数:batch和subdivisions是比较令人费解的,如上所示。一般地,batch就是一次输入多少图片到神经网络中来计算loss,并反向update gradients。 但在darknet代码里面,含意稍微有些不同。
实际上网络是喂入batch张图片进行训练(前向推理和反向传播),但是升级权值是在cfg中batch数目结束后进行的。它把平常所说的mini-batch SGD的batch分割成两个部分含义。前面是小batch图片训练,后面再是大batch训练后更新网络。 这样做的用意,应该是为了省内存吧。 每次计算的图片数目 = batch/subdivisions,然后把结果合起来也就是一个batch更新模型一次。
换个角度,如果内存足够的话,且想提高训练速度的话,应该是提高cfg中的batch值,并适当较少subdivision,这样net->batch适当变大,意味着每次参加训练的图片数目增加,循环训练次数subdivision变少。 以文中数值例子而言,将64和16改成64和8比较适宜些。

第二个要改的点就是classes,修改为你要训练数据的类别数量,应该是有三处。

第三个要改的地方就是在yolo层的上一层的filters,修改为(your_classes + 5)* 3,比如我这里classes_num = 2,那么我就修改为filters=21。因为有三个yolo层,那么就应该要修改三处。
3.7 开始训练
cd darknet-master
./darknet detector train cfg/fenhe.data cfg/fenhe_net.cfg backup/yolov3.weights -gpus 0,1
注:
第一个参数:上述data文件路径
第二个参数:上述yolov3.cfg文件路径
第三个参数:这个参数可以选择不填,如果想要使用预训练权重文件,就把预训练文件路径放进去就好
第四个参数:选取指定的显卡
3.8 测试
cd darknet-master
./darknet detector test cfg/fenhe.data cfg/fenhe_net.cfg backup/yolov3.weights data/img.jpg -thresh 0.5 -gpus 0,1
注:
第一个参数:上述data文件路径
第二个参数:上述yolov3.cfg文件路径
第三个参数:这个参数可以选择不填,如果想要使用预训练权重文件,就把预训练文件路径放进去就好
第四个参数:测试图片路径
第五个参数:阈值大小(可选填)
第六个参数:选取指定的显卡
部分转载于:https://zhuanlan.zhihu.com/p/45852709








