您现在的位置是:主页 > news > 宝塔可以做二级域名网站么/成都网站快速开发
宝塔可以做二级域名网站么/成都网站快速开发
![]() admin2025/4/29 7:08:35【news】
admin2025/4/29 7:08:35【news】
简介宝塔可以做二级域名网站么,成都网站快速开发,建立网站买空间哪家好,网站五合一建设1.数组的存储方式和缺点 1、数组的存储特点:在一个连续的内存空间里面,存放着某些特点的数据,把这些数据集合在某个内存空间中。 数组非常明确的特点是:数组是一个整体,每一个元素的地址是连续的。结构体其实也类似&…
宝塔可以做二级域名网站么,成都网站快速开发,建立网站买空间哪家好,网站五合一建设1.数组的存储方式和缺点
1、数组的存储特点:在一个连续的内存空间里面,存放着某些特点的数据,把这些数据集合在某个内存空间中。
数组非常明确的特点是:数组是一个整体,每一个元素的地址是连续的。结构体其实也类似&…
1.数组的存储方式和缺点
1、数组的存储特点:在一个连续的内存空间里面,存放着某些特点的数据,把这些数据集合在某个内存空间中。
- 数组非常明确的特点是:数组是一个整体,每一个元素的地址是连续的。
- 结构体其实也类似,结构体也是一个整体,抛开结构体内存中那部分空闲的内存不讲,各个成员变量也是有序存放的。
- 结构体数组也很明显,每个结构体是数组的元素,它们的地址也是连续的。
2、连续存储的缺点:
- 知识点:对于数据,我们希望能对它们做四种操作:“增”、“删”、“改”、“查”。显然,对于数组这种数据结构,“增”、“删”这两个操作很难实现,有时会涉及到整个数组的挪动。如图:

- 缺点1:不灵活,增删数据时运算量变大。
- 缺点2:不管是静态分配内存还是动态分配内存,数组都是一口气申请了大部分空间。
2.链表是普通结构体的应用,为我们开发带来便利
1、链表举例:链表的每一个数据是结构体变量,每个数据之间用结构体指针的方式将数据串起来。
- 示例:链表中的数据中都存放着下一个数据的地址 。

#include <stdio.h> struct A {int idata;struct A* p; }; int main(int argc, char const *argv[]) {struct A a = {1}; struct A b = {2}; struct A c = {3};struct A d = {4};a.p = &b; //数据a指向数据bb.p = &c; //数据b指向数据cc.p = &d; //数据c指向数据dreturn 0; }
2、链表的“增、删数据”操作方法:
- 删去其中一个数据:以删去数据b为例,只需要将数据a的指向从b改为c。后面的数据不需要动。
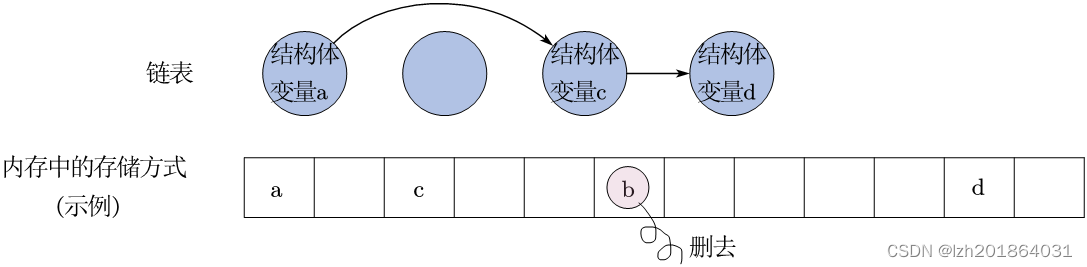
#include <stdio.h> struct A {int idata;struct A* p; }; int main(int argc, char const *argv[]) {struct A a = {1}; struct A b = {2}; struct A c = {3};struct A d = {4};a.p = &b;b.p = &c;c.p = &d;/* 删去链表中的数据b */a.p = &c; //只需要将数据a的指向从b改为creturn 0; } - 增加一个数据:以在数据a和数据b之间增加数据e为例,只需要将数据a的指向从b改为e,将数据e指向b。后面的数据不需要动。
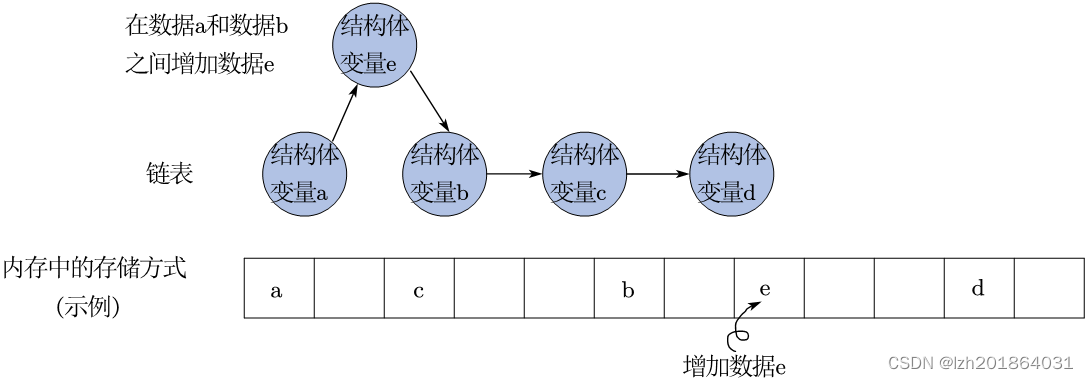
#include <stdio.h> struct A {int idata;struct A* p; }; int main(int argc, char const *argv[]) {struct A a = {1}; struct A b = {2}; struct A c = {3};struct A d = {4};a.p = &b;b.p = &c;c.p = &d;/* 在数据a和数据b之间增加链表数据e */struct A e = {5};a.p = &e; //只需要将数据a的指向从b改为ee.p = &b; //再将数据e指向数据breturn 0; }
3.实现链表的第一个代码——与数组进行比较
代码心得:
- gcc编译时,我们有加-o,如果没有写-o,那么会默认生成一个a.out文件。
- 目前单纯只讲结构体,还没讲链表。所以只能一个一个定义数据,定义结构体变量时,可以把里面的结构体指针初始化成NULL。
- 链表数据内部定义结构体指针变量的时候,可以形象的给这个指针起个名字,叫做next。
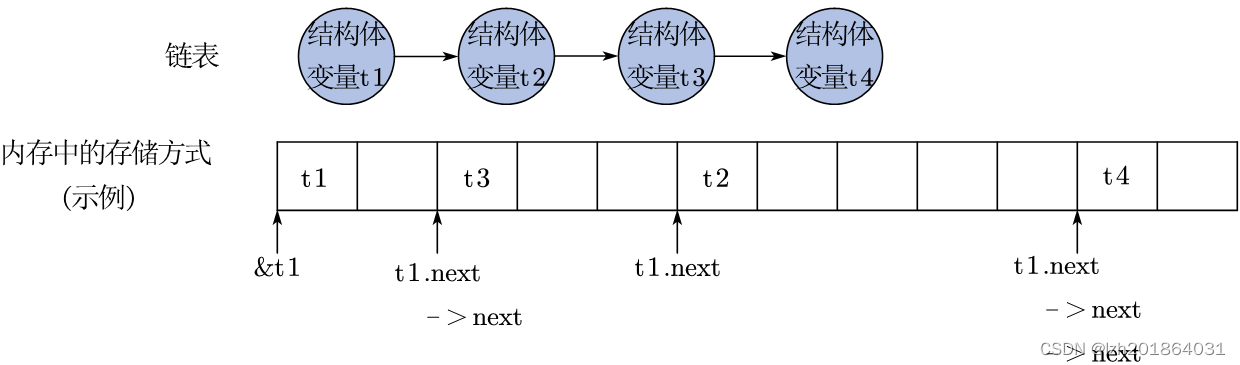
- 在用链表前一个数据访问下一个数据时,我们先通过点运算符取到下一个结构体的地址,再用剑号运算符取出这个结构体中的成员变量的值。其中,可以不加小括号,因为点运算符和剑号运算符的结合方向都是从左向右,比如:t1.next->idata。
- 在Ubuntu中,在用VI工具编辑代码时,用 :set nu 指令,显示行号。
1、用链表头访问链表:
- 知识点:数组里的数据是连续的,只需要知道数组头,就能输出整串数据;而对于分散的数据,通过链表才能用一个数据访问其他不连续存放的数据。
- 类似于数组头是数组的首地址,链表的第一个数据的首地址称为链表头。拿到链表头,通过next的方式就能遍历整个链表。
代码心得:
- 通常我们用head代表链表头。
- 你会发现在上面使用链表头t1并通过next访问链表数据时,有个特点,从t1到t1.next增加了一个next,从t1.next到t1.next->next增加了一个next,因此肯定能够通过循环的方式通过链表头访问链表数据。
#include <stdio.h> struct Test {int idata;struct Test *next; }; int main(int argc, char const *argv[]) {/* 用数组的方式存放1、2、3 */int i;int arr[] = {1,2,3};int len = sizeof(arr) / sizeof(arr[0]);for(i=0; i<len; i++){ //只需要知道数组头,就能访问数组中所有数据printf("%d ", arr[i]);}putchar('\n');/* 用链表的方式存放1、2、3 */struct Test t1 = {1,NULL};struct Test t2 = {2,NULL};struct Test t3 = {3,NULL};t1.next = &t2; //通过链表,才能通过一个数据访问其他不连续存放的数据t2.next = &t3; puts("use t1 print three numbers");printf("%d %d %d\n", t1.idata, t1.next->idata, t1.next->next->idata);return 0; }
2、链表的完善(如何让链表头往后走):
- 知识点:
- 链表中只有链表尾巴那个数据里面的指针是NULL。

- 对于数组来说,我们不知道遍历到什么时候结束(防止越界),所以遍历数组的时候需要两个参数(数组头和数组长度)。
- 对于链表来说,我们知道遍历什么时候结束(链表尾巴里的指针是NULL),所以遍历链表的时候只需要一个参数(链表头)。
- 对于数组arr来说,可以用数组名偏移的方式访问数组元素,也就是说每次让数组名这个“指针”往后走(arr+1)。而对于链表头head来说,它的后面指的是head->next(就是后一个链表数据的地址)。

- 链表中只有链表尾巴那个数据里面的指针是NULL。
- 封装遍历链表的API:
思路: f1. 封装遍历链表的API: void printLink(struct Test *head); 形参head用来接收链表头的地址f1.1 while死循环f1.1.1 判断结构体指针head是否不等于NULLf1.1.1.1 如果是,说明没有访问到链表尾巴f1.1.1.1.1 打印链表数据: f1.1.1.1.2 修改代表链表数据地址的循环变量head: head = head->next;f1.1.1.2 否则,说明已经访问到链表尾巴那么,用break提前退出循环 代码: #include <stdio.h> struct Test {int idata;struct Test *next; }; void printLink(struct Test *head); int main(int argc, char const *argv[]) {struct Test t1 = {1,NULL};struct Test t2 = {2,NULL}; struct Test t3 = {3,NULL};struct Test t4 = {4,NULL};t1.next = &t2; t2.next = &t3; t3.next = &t4; puts("use t1 print three numbers");//printf("%d %d %d\n", t1.idata, t1.next->idata, t1.next->next->idata);printLink(&t1);return 0; } void printLink(struct Test *head) {while(head != NULL){printf("%d ", head->idata);head = head->next;}putchar('\n'); }








