您现在的位置是:主页 > news > 做网站的网址/广州优化seo
做网站的网址/广州优化seo
![]() admin2025/4/30 2:31:48【news】
admin2025/4/30 2:31:48【news】
简介做网站的网址,广州优化seo,wordpress 权限设置,互联网域名注册插入并保存文档 插入是向MongoDB中添加数据的基本方法。可以使用Insert方法向目标集合插入一个文档:db.foo.insert({"bar" : "baz"})。 如果向集合中插入多个文档,使用批量插入。可以使用batchInsert函数实现批量插入,…
插入并保存文档
插入是向MongoDB中添加数据的基本方法。可以使用Insert方法向目标集合插入一个文档:db.foo.insert({"bar" : "baz"})。
如果向集合中插入多个文档,使用批量插入。可以使用batchInsert函数实现批量插入,它接受一个文档数组作为参数:db.foo.batchInsert([{"_id" : 0}, {"_id" : 1}, {"_id" : 2}])。不能在单次请求中将多个文档批量插入到多个集合中。要是只导入原始数据(例如从数据feed或者MySQL中导入),可以使用命令行工具,如mongoimport,而不是批量插入。另一方面,可以使用批量插入在将数据存入MongoDB之前对数据做一些小的修整(将日期转换为日期类型,或添加自定义的"_id")。如果在执行批量插入的过程中有一个文档插入失败,那么在这个文档之前的所有文档都会成功插入到集合中,而这个文档以及之后的所有文档全部插入失败。
插入数据时,MongoDB只对数据进行最基本的检查:检查文档的基本结构,如果没有“_id”字段,就自动增加一个。检查大小就是其中一项基本结构检查:所有文档都必须小于16MB(这个值是MongoDB设计者人为设定的)。如果要查看doc文档的BSON大小(单位为字节),可以在shell中执行Object.bsonsize(doc)。由于MongoDB只进行最基本的检查,所以插入非法数据很容易。但是主流语言的所有驱动程序(以及大部分其他语言的驱动程序),都会在将数据插入到数据库之前做大量的数据校验(比如文档是否过大,文档是否包含非UTF-8字符串,是否使用不可识别的类型)。
删除文档
命令db.foo.remove()会删除foo集合中的所有文档。但是不会删除集合本身,也不会删除集合的元信息。remove函数可以接受一个查询文档作为可选参数。给定这个参数以后,只有符合条件的文档才被删除。例如,假设要删除mailing.list集合中所有"opt-out"为true的人:db.mailing.list.remove({"opt-out" : "true"})。
清空整个的集合,且所有元数据也删除,使用drop可直接删除db.tester.drop()。插入一百万测试数据->使用remove和drop删除->显示时间



更新文档
文档存入数据库后,可以用update方法更新。update有两个参数,一个是查询文档,用于定位需要更新的目标文档;另一个是修改器(modifier)文档,用于说明要对找到的文档进行哪些修改。更新操作是不可分割的:若是两个更新同时发生,先到达服务器的先执行,接着执行另外一个。所以,两个需要同时进行的更新会迅速链接完成,此过程不会破坏文档;最新的更新会取得“胜利”。
文档替换
文档替换:最简单的更新就是用一个新文档完全替换匹配的文档。例如对下面的用户文档做调整,将friends和enemies两个字段移到relationships子文档中。


修改器
使用修改器:通常文档只会有一部分要更新,可以使用原子性的更新修改器(update modifier),指定对文档中的某些字段进行更新。更新修改器是种特殊的键,用来指定复杂的更新操作,比如修改、增加或者删除键,还可以是操作数组或者内嵌文档。
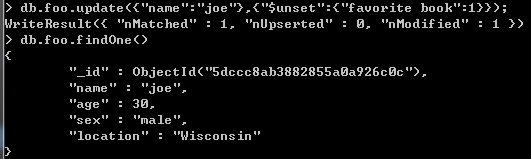
如下图使用"$inc“修改器增加“pageviews”的值,使用修改器时,“_id”的值不能改变。(整个文档替换时可改变”_id")

set修改器
$set修改器:用来指定一个字段的值。如果这个字段不存在,则创建它。这对更新模式或者增加用户定义的键来说非常方便。

用$set甚至可以修改键的类型。例如,如果用户觉得喜欢很多本书,就可以将“favorite book”键的值变成一个数组:

可以使用$unset可以用于将键值对完全删除:
inc修改器
"$inc“修改器用来增加减少已有键的值,或者该键不存在那就创建一个。”$inc"只能用于整型、长整型或双精度浮点型的值。要是用在其他类型的数据上就会导致操作失败、例如null、布尔类型以及数字构成的字符串。

数组修改器
有一大类很重要的修改器可用于操作数组。数组是常用且非常有用的数组结构:它们不仅是可通过索引进行引用的列表,而且还可以作为数据集来用。
添加元素:如果数组已经存在,“$push”会向已有的数组末尾加入一个元素,要是没有就创建一个新的数组。例如,假设要存储博客文章,要添加一个用于保存数组的“comments”(评论)键。可以向还不存在的“comments”数组添加一条评论,这个数组会被自动创建,并加入一条评论。


可以使用$each子操作符,通过一次$push操作添加多个值。比如下面就将三个新元素添加到数组中。如果指定的数组中只含有一个元素,那这个操作就等同于没有使用$each的普通$push操作。
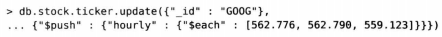
如果希望数组最大长度是固定的,可以将“$slice”和"$push"组合使用,“$slice”的值必须是负整数,可以保证数组不会超出设定好的最大长度。下面的例子会限制数组只包含最后加入的10个元素。

如果数组的元素数量小于10,那么所有元素都会保留。如果数组的元素数量大于10,那么只有最后10个元素会保留。
最后,可以在清理元素之前使用$sort,只要向数组中添加子对象就需要清理。下面例子根据“rating”字段的值对数组中的所有对象进行排序,然后保留前10个。注意,不能只将$slice或$sort与$push配合使用,且必须使用$each。

将数组作为数据集使用:可以将数组作为数据集使用,从而保证数组内的元素不会重复。可以在查询文档中用“$ne”来实现。例如,要是作者不在引文列表中,就添加进入,可以这么做:

也可以用“$addToSet”来实现,要知道有些情况“$ne”根本行不通,有些时候更适合“$addToSet”。例如下面表示用户的文档,对电子邮件地址的数据集进行添加。

将“$addToSet”和“$each”组合起来,可以添加多个不同的值,而用“$ne”和“$push”组合就不能实现。

删除元素:若是把数组看成队列或者栈,可以用$pop,这个修改器可以从数组任何一端删除元素。{"$pop":{"key":1}}从数组末尾删除一个元素。{"$pop":{"key":-1}}从数组头部删除一个元素。有时需要基于特定条件来删除元素,而不仅仅是依据元素位置,这时可以使用$pull。$pull会将所有匹配的文档删除,而不是只删除一个。对数组[1,1,2,1]执行pull 1,结果得到只有一个元素的数组[2]。例如,有一个无序的待完成事项列表:
要是想把洗衣服放到第一位,可以从列表中删除。

基于位置的数组修改器:若是数组有多个值,而想对其中的一部分进行操作,就需要一些技巧。有两种方法操作数组中的值:通过位置或者定位操作符()。数组下标都是以0开头的,可以将下标直接作为键来选择元素。例如,这里有个文档,其中包含由内嵌文档组成的数组,比如包含评论的博客文章。如果想增加第一个评论的投票数量,可以这么做:很多情况下,不预先查询文档就不能知道要修改的数组的下标。为了克服这个困难,MongoDB提供了定位操作符(‘)。数组下标都是以0开头的,可以将下标直接作为键来选择元素。例如,这里有个文档,其中包含由内嵌文档组成的数组,比如包含评论的博客文章。   如果想增加第一个评论的投票数量,可以这么做:  很多情况下,不预先查询文档就不能知道要修改的数组的下标。为了克服这个困难,MongoDB提供了定位操作符(`)。数组下标都是以0开头的,可以将下标直接作为键来选择元素。例如,这里有个文档,其中包含由内嵌文档组成的数组,比如包含评论的博客文章。如果想增加第一个评论的投票数量,可以这么做:很多情况下,不预先查询文档就不能知道要修改的数组的下标。为了克服这个困难,MongoDB提供了定位操作符(‘`),用来定位查询文档已经匹配的数组元素,并进行更新。例如,要是用户John把名字改为Jim,就可以用定位符替换他在评论中的名字。定位符只更新第一个匹配的元素。如果John发表了多条评论,那么他的名字只在第一条评论中改变。

upsert
upsert是一种特殊的更新。要是没有找到符合更新条件的文档,就会以这个条件和更新文档为基础创建一个新的文档。如果找到了匹配的文档,则正常更新。upsert非常方便,不必预置集合,同一套代码既可以用于创建文档又可以用于更新文档。
使用记录网站页面访问次数的例子,不使用upsert,先对数据库进行查询,然后选择更新或者插入。但是要是多个进程同时运行这段代码,还会遇到同时对给定URL插入多个文档这样的竞态条件。

使用upsert,可以避免竞态问题,又可以缩减代码量(update的第3个参数表示这是个upsert)
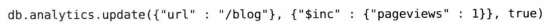
这行代码和之前的代码作用完全一样,但它更高效,且是原子性的。创建新文档会将条件文档作为基础,然后对它应用修改器文档。例如,要是执行一个匹配键并增加对应键值的upsert操作,会在匹配的文档上进行增加:

upsert创建一个“rep”值为25的文档,随后将这个值加3,最后得到“rep”为28的文档。要是不指定upsert选项,{“rep”:25}不会匹配任何文档,也就不会对集合进行任何更新。要是再次运行这个upsert(条件为{“rep”:25}),还会创建一个新文档。这是因为没有文档满足匹配条件(唯一一个文档的“rep”值是28)。
需要在创建文档的同时创建字段并为它赋值,但是在之后的所以有更新操作中,这个字段的值都不再改变。$setOnInsert只会在文档插入时设置字段的值。

如果再次运行这个更新,会匹配到这个已存在的文档,所以不会再插入文档,因此createdAt字段的值也不会改变:

更新多个文档
默认情况下,更新只能对符合匹配条件的第一个文档执行操作。要是有多个文档符合条件,只有第一个文档会被更新,其他文档不会发生变化。要更新所有匹配的文档,可以将update的第4个参数设置为true。多文档更新对模式迁移非常有用,还可以在对特定用户发布新功能时使用。
例如要送给在指定日期过生日的所有用户礼物,就可以使用多文档更新,将gift增加到他们的账号。

想要知道多文档更新到底更新了多少文档,可以运行getLastError命令(可以理解为返回最后一次操作的相关信息),键n的值就是被更新文档的数量。这里n为5,说明有5个文档被更新,updatedExisting为true,说明是对已有的文档进行更新。

返回被更新的文档
可以通过findAndModify命令得到被更新的文档,这对于操作队列以及执行其他需要进行原子性取值和赋值的操作来说,十分方便。
假设每个进程用如下形式的文档表示:status是一个字符串,值可以是READY、RUNNING或DONE。

需要找到状态为READY具有最高优先级的任务,运行相应的进程函数,然后将其状态更新为DONE。需要查询已经就绪的进程,按照优先级排序,然后将优先级最高的进程的状态更新为RUNNING,完成后,把状态该位DONE。

这段程序可能会导致竞态条件。假设有两个线程正在运行,A线程读取了文档,B线程在A将文档状态改为RUNNING之前也读取了同一个文档,这样两个线程会运行相同的处理过程。虽然可以在更新查询中进程状态检查来避免这一问题。
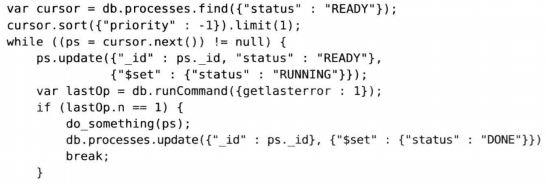

findAndModify能够在一个操作中返回匹配结果并且进行更新,返回文档中的状态仍然为READY,因为findAndModify返回的是修改之前的文档。要是再进行一次查询,会发现这个文档的status已经更新成了RUNNING。


程序可以写成下面:

findAndModify命令有很多可以使用的字段:
| 字段 | 解释 |
|---|---|
| findAndModify | 字符串,集合名 |
| query | 查询文档,用于检索文档的条件 |
| sort | 排序结果的条件 |
| update | 修改器文档,用于对匹配的文档进行更新 |
| remove | 布尔类型,表示是否删除文档 |
| new | 布尔类型,表示返回更新前的文档还是更新后的文档。默认是更新前的文档 |
| fields | 文档中需要返回的字段 |
| upsert | 布尔类型,值为true时表示这是一个upsert。默认为false |
查询
MongoDB使用find来查询,查询就是返回一个集合中文档的子集,子集的范围从0个文档到整个集合。find的第一个参数决定了要返回哪些文档,这个参数是一个文档,用于指定查询条件。空的查询文档({})会匹配集合的全部内容。要是不指定查询文档,默认就是{}。向查询文档中添加键值对时,就意味着限定了查询条件。
通过find(或findOne)的第二个参数来指定想要的键。例如,如果只对用户集合的username和email键感兴趣,可以用如下查询,默认情况下“_id”这个键总是被返回,即便是没有指定要返回这个键。

也可以用第二个参数来剔除查询结果中的某些键值对。例如,不希望结果还有fatal_weakness键。
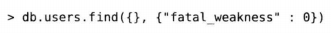
也可以使用这种方式将“_id”键剔除。
查询条件
比较操作符
$lt $lte $gt $gte就是全部的比较操作符,分别对应<、<=、>和>=。可以将其组合起来以便查找一个范围的值。例如,查询18-30岁的用户,db.users.find({"age":{"$gte":18, "$lte":30}})。这样的范围查询对日期尤为有用。例如,要查询在2007年1月1日前注册的人,可以像下面这样:

可以对日期进行精确匹配,但是用处不大,因为文档中的日期是精确到毫秒的。而我们通常是想得到一天、一周或一个月的数据,这样的话,使用范围查询就很必要。
对于文档的键值不等于某个特定值的情况,就要使用另外一种条件操作符$ne,它表示不相等。若是想要查询所有名字部位joe的用户,可以像下面这样查询:db.users.find({"username":{"$ne":"joe"}})。
OR查询
MongoDB中有两种方式进行OR查询:$in可以用来查询一个键的多个值;$or可以在多个键中查询任意的给定值。
如果一个键需要与多个值进行匹配,用$in操作符加一个条件数组。例如抽奖中奖号码是725、542和390。要找到全部的中奖文档,可以构建如下插叙:db.raffle.find({"ticket_no":{"$in":[725,542,390]}})。这会匹配user_id等于12345的文档,也会匹配user_id等于joe的文档。要是$in对应的数组只有一个值,那么和直接匹配这个值效果一样。例如{ticket_no:{$in:[725]}}和{ticket_no:725}效果一样。与$in相对于的是$nin,表示返回与数组中所有条件都不匹配的文档。
如果想找到ticket_no为725或winner为true的文档,应使用$or。$or接受一个包含所有可能条件的数组作为参数。
条件语句是内层文档的键,修改器则是外层文档的键。一个键可以有任意多个条件,但是一个键不能对应多个更新修改器。有一些元操作符也可位于外层文档中,比如$and $or $nor。
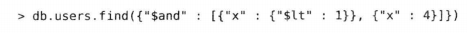
这个查询会匹配x字段值小于等于1且等于4的文档。虽然看似矛盾,但是如果x字段的值是数组{"x":[0,4]},那么这个文档就与查询条件相匹配。
特定类型的查询
null不仅仅会匹配某个键的值为null的文档,而且会匹配不包含这个键的文档。



如果仅想匹配键值为null的文档,既要坚持该键的值是否为null,还要通过$exists条件判定键值已存在:
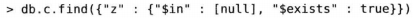
正则表达式
MongoDB使用Perl兼容的正则表达式库来匹配正则表达式,比如匹配各种大小写组合形式的joe。
查询数组
查询数组元素与查询标量值是一样的。比如有一个水果列表,直接查询可以匹配该文档。
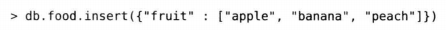

使用整个数组进行精确匹配,对于缺少元素或者冗余元素将不匹配。
匹配
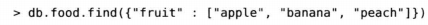
不匹配 缺少
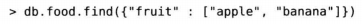
不匹配 顺序
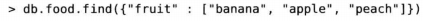
如果需要通过多个元素匹配数组,就用$all,这样会匹配一组元素。

找到既有apple又有banana的文档:

如果想匹配数组特定位置的元素,需使用key.index语法指定下标:

$size可以用来查询特定长度的数组,但是不能和其他查询条件组合使用

find的第二个参数是可选的,可以指定需要返回的键。而$slice操作符可以返回某个键匹配的数组元素的一个子集。假设现在有一个博客文章的文档,希望返回前10条评论:
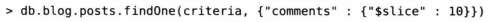
返回后10条评论:
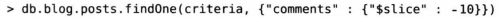
也可以指定偏移以及希望返回的元素数量,来返回元素集合中间位置的某些结果:
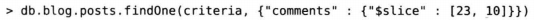
这个操作会跳过前23个元素,返回第24-33个元素。如果数组不够33个元素,则返回第23个元素后面的所有元素。
数组查询和范围查询的相互作用
文档中的标量必须与查询条件中的每一条语句相匹配。但是假如某文档的x字段是一个数组,如果x键的某个元素与查询条件的任意一条语句相匹配(查询条件中的每条语句可以匹配不同的数组元素),那么这个文档也会被返回。

如果希望找到x键的值位于10和20之间的所有文档,直接想到的查询方式是使用db.test.find({"x":{"$gt":10,"$lt":20}}),返回为

5何25都不位于10和20之间,但是这个文档也返回了,因为25与查询条件中第一个语句相匹配,5与查询条件中第二个语句匹配。
可以使用$elemMatch要求MongoDB同时使用查询条件中的两个语句与一个数组元素进行比较。但是它不会匹配非数组元素。

如果当前查询的字段上创建过索引,可以使用min和max将查询条件遍历的索引范围限制为gt何lt的值。这个查询只会遍历值位于10和20之间的索引,不再与5和25进行比较。

查询内嵌文档
两种方法可以查询内嵌文档:查询整个文档,或者只针对其键值对进行查询。

通常只针对内嵌文档的特定键值进行查询,可使用点表示法查询内嵌文档的键
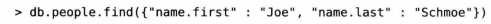
where查询
$where子句可以在查询中执行任意的JavaScript,比如比较文档中两个键的值是否相等。

这里希望找出具有两个键相同值的文档。比如第二个文档中,spinach和watermelon的值相同。

游标
数据库使用游标返回find的执行结果,客户端对游标的实现通常能够对最终结果进行有效控制。
要想从shell中创建一个游标,首先要对集合填充一些文档,然后对其执行查询,并将结果分配给局部变量。
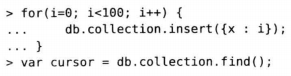
要迭代结果,可以使用游标的next方法。也可以使用hasNext来查看游标中是否还有其他结果。

游标类还实现了JavaScript的迭代器接口,可以在forEach循环中使用

调用find时,shell并不立即查询数据库,而是等待真正开始要求获得结果时才发送查询,这样在执行之前可以给查询附加额外的选项。几乎游标对象的每个方法都返回游标本身,这样就可以按任意顺序组成方法链。

此时,查询还没有真正执行,所有这些函数都只是构造查询。假设执行如下操作:cursor.hasNext(),查询被发往服务器。shell立刻获取前100个结果或者前4MB数据,这样下次调用next或者hasNext时就不必再次连接服务器取结果了。客户端用光了第一组结果,shell会再次联系数据库,使用getMore请求提取更多结果。getMore请求包含一个查询标识符,向数据库询问是否还有更多的结果,如果有,则返回下一批结果。
limit skip sort
limit函数->限制结果数量,比如db.c.find().limit(3)。limit指定的是上限而非下限。
skip函数->略过前几个结果,比如db.c.find().skip(3)。略过前三个匹配文档,返回余下的文档。
sort函数接受一个对象作为参数,这个对象是一组键值对,键对应文档的键名,值代表排序的方向。排序方向可以是1(升序)或-1(降序)。如果指定多个键,则按照这些键被指定的顺序逐个排序。
例如,要按照username升序及age降序排序:

游标生命周期
在服务器端,游标消耗内存和其他资源。游标遍历尽结果后,或者客户端发来消息要求终止,数据库会释放这些资源。还有一些情况导致游标终止(随后被清理)。首先,游标完成匹配结果的迭代时,它会清除自身。另外,如果客户端的游标不在作用域内,驱动程序会向服务器发送一条特别的消息,让其销毁游标。如果用户没有迭代完结果,且游标仍在作用域内,10分钟内其没有使用,数据库游标也会自动销毁。
系列文章:
第一篇 MongoDB权威指南读书笔记——概念








